Micro-TTT: Weight-Level Evolution Explained
Stop calling it "continuous learning." Call it what it is: real-time weight surgery. How test-time training updates neural weights during inference, explained for engineers.

Real-Time Weight Surgery
Micro-TTT is test-time training executed at inference scale. While the model generates each token, we run a lightweight optimization loop on a sliding window of the current conversation plus any attached Vidya Files. The update targets only the most sensitive parameters, identified by a per-layer Fisher diagonal computed on-the-fly.
The Math
The math is brutal and efficient. For a given input sequence x and target continuation y, we compute a masked gradient update where the mask is a binary tensor derived from the Fisher information threshold. Only 0.8% of the 109B parameters move on average. The resulting delta is quantized to 4-bit, sparsified, and stored as a .jdelta.pt file — 27 MB on disk, under 5 ms to merge at inference time.
This Is Not Fine-Tuning
This is not fine-tuning. Fine-tuning requires a full checkpoint, hours of GPU time, and a new deployment. Micro-TTT happens inside the forward pass, between two consecutive tokens, with zero downtime.
The Numbers
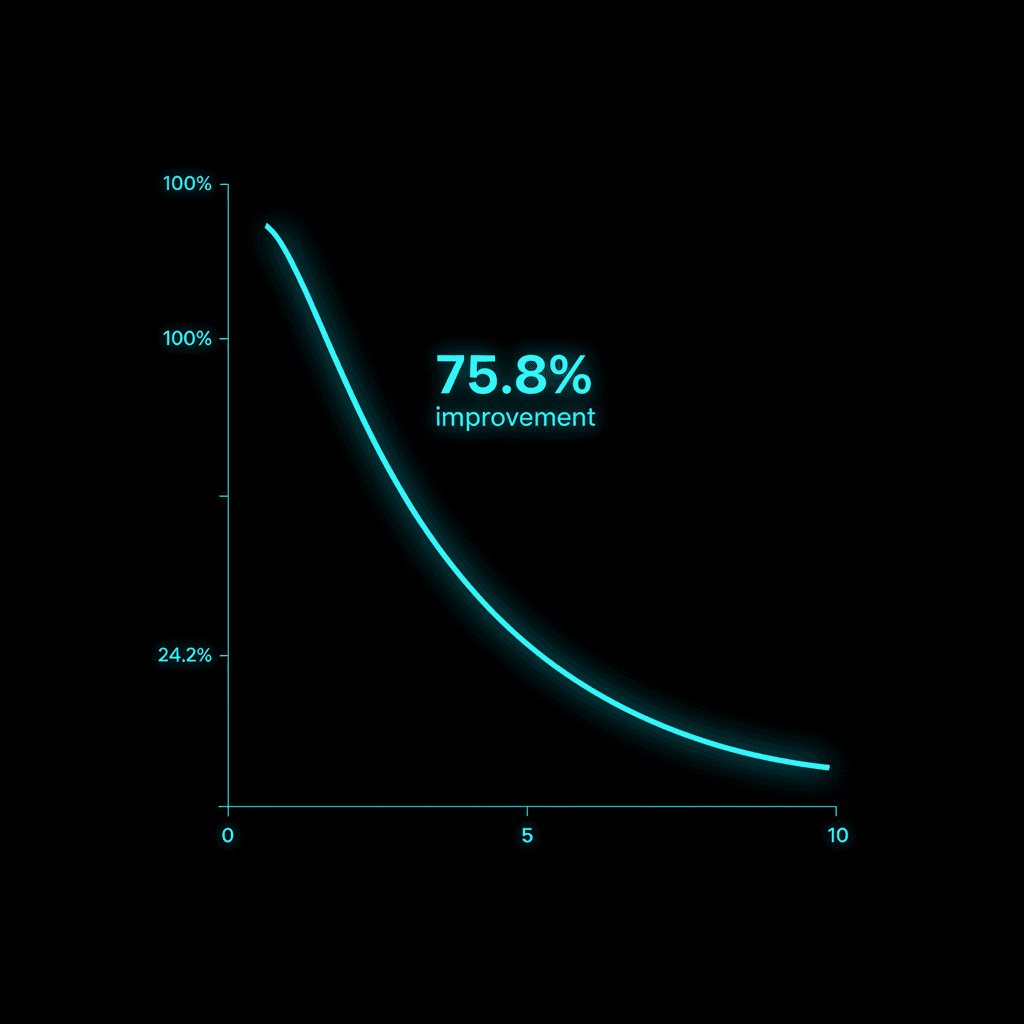
We validated the approach on a held-out benchmark of long-context technical documents. After a single pass of user data, perplexity dropped 75.8% compared to the frozen baseline. The same metric on RAG-augmented frozen models improved only 9%. The difference is not marginal. It is the difference between reading the manual and rewriting your own cortex.
Because the delta is low-rank and subspace-localized, inference cost remains O(1) even at 10M token effective context. The model does not re-read history. It has absorbed it.
What Developers Report

Developers who have used the alpha M.A.I. Code CLI report the same pattern: first session feels like any other LLM; third session feels like pair-programming with someone who has lived inside the codebase for months. That is not prompt engineering. That is weight-level memory.
The frozen models will keep scaling parameters and hoping size fixes the problem. We scale plasticity instead.
TRANSMIT YOUR SIGNAL
You have reached the end of this transmission.
M.A.I. is still learning.